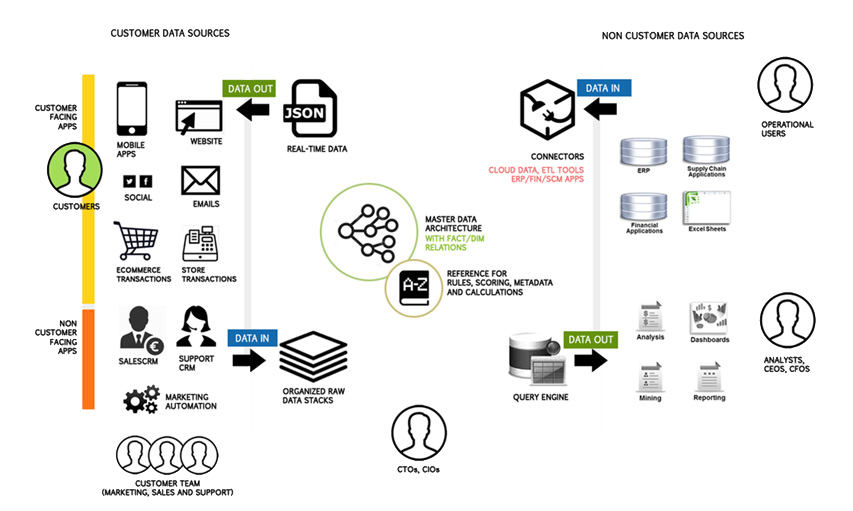
Connecting data sources
In today's data environment, data is collected across sources: Mainframes, Legacy systems,
Back office apps, Offline databases, spreadsheets, online applications, cloud applications
and third party web services. Plumb5's ready connectors can help organizations quickly
integrate data from online/cloud sources and spreadsheets. You can work with the Plumb5 team
to customize data import and ensure that you have tagged every single data and created a
complete data master.
Data Tagging with Plumb5 is a one-time activity, post which schedulers can be enabled to
maintain data synchronization at all times to deliver real-time insights and reports built
over unified data .
Integration that supports bi-directional data flow
Integrating all your data sources to the unification platform should allow seamless data flow
in both directions. Plumb5 platform is designed to facilitate data flow either to the
internal users for operational insights or to the customer, where real-time insights matter
to drive personalization
As depicted in the above diagram, the core of Plumb5 has a rule engine and a data-aware
structure that binds data across all sources which helps in maintaining unification. This
technique takes out data redundancy and stacks unique data sequenced by time parameters. It
connects to the respective point sources using a tag system and synchronizes data for
synthesis of insights and delivered back to any point system based on the defined process.